How Enclave works¶
Let's briefly cover the high-level differences between legacy connectivity and Enclave before we dive in to the detail.
Legacy VPNs and Identity-Based-Networks function by moving your traffic through a single concentrator before connecting on to the actual resource you want to use, i.e. the classic hub and spoke model:
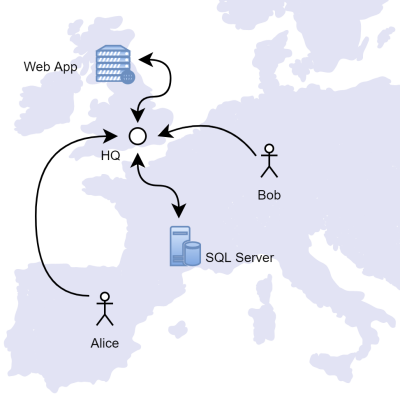
There are a number of downsides to a classic VPN around scalability, latency, security on a publicly-exposed endpoint, and more.
Enclave, on the other hand, uses a peer-to-peer virtual overlay model; instead of having any central concentrator, all connectivity is built direct, between peers, more like this:
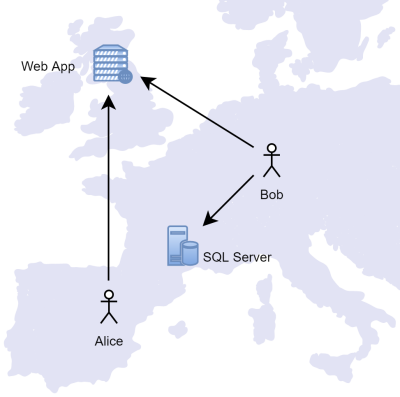
This means there is no additional component needed in your network to route traffic, reducing maintenance, bottlenecks, and costs. It also means we don't see any of your data (because it moves directly between your devices), and you get the lowest latency possible.
Enclave is primarily an agent-based solution, where our agent is installed on each device that wishes to connect to your virtual Enclave Network. There are exceptions to that rule (namely Enclave Gateway), but generally you will need an agent on each device.
Once the agent is deployed and enrolled in your organisation, you define policy that allows it to connect to any other peer in your virtual network, from behind completely closed firewalls. Enclave doesn't require any open ingress ports in order to function, and can be deployed without needing any changes to the existing network.
Building connectivity¶
As I just said, Enclave doesn't need any open ingress ports to function; so how do we build that connectivity without moving traffic through a middleman?
Our connectivity is built on the principles established in the ICE (Interactive Connectivity Establishment) RFC, that underpins the way in which direct connections are built across the internet, most commonly in video calling platforms.
The fundamental principle is that some hosted component (called the Discovery Service in our architecture), knows the reachable endpoints of both peers that wish to communicate, and an introduction takes place when policy allows, informing both peers of the reachable addresses of the other peer.
Both peers then initiate TCP and/or UDP hole-punching to achieve a connection.
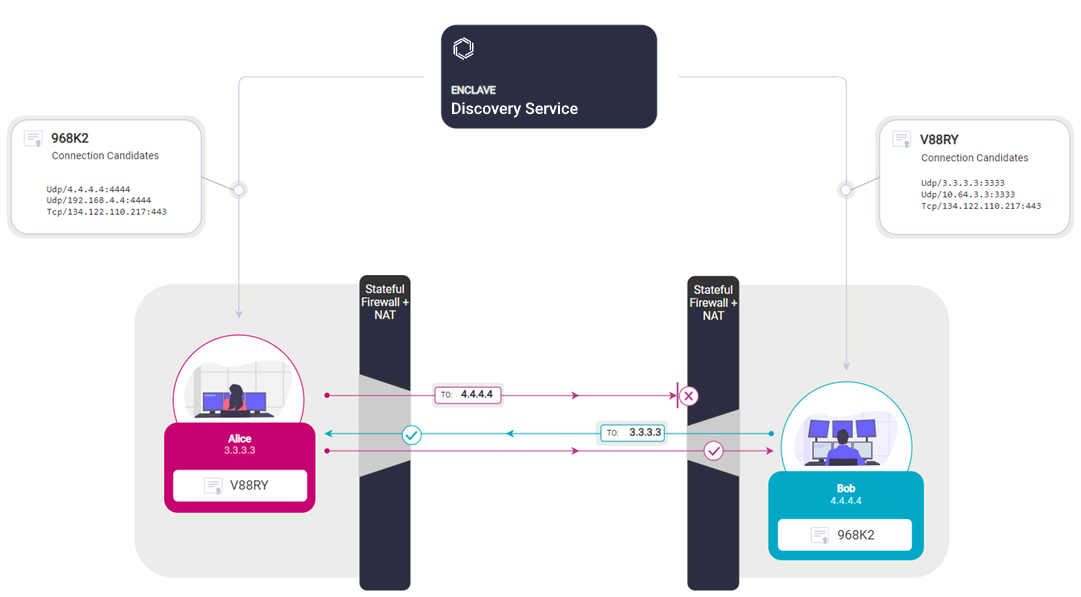
The steps for this process (in brief) are:
- Alice + Bob Authenticate with the Discovery Service, and provide "Connection Candidate" addresses.
- Discovery Service determines, "should Alice talk to Bob?"
- Broker "introduces" Alice to Bob (and vice versa)
- Alice and Bob send handshake packets to each other at the same time.
- The stateful firewall and NAT devices between Alice and Bob see these handshake packets as return packets from each other's destination.
- Cryptographic handshake takes place.
- Tunnel established.
Once that tunnel is established, data can flow directly between the two peers, end-to-end encrypted, with (ideally) no traffic moving through our platform. There is a caveat to that, which is when relays are required. We'll cover this in the next section.
Info
Wondering what the V88RY and 968K2 are in that diagram? Check out our section on Identity and Cryptography.
Connection candidates¶
You may note in the above diagram that the set of "connection candidates" provided to each peer includes three different types. Each of these address types have a different "priority".
When we build connectivity between peers, we try all of the candidates we know about, in priority order, and choose the highest priority tunnel that successfully establishes.
Public IP addresses¶
The candidate set includes the public IP address and port number of the system, as they appear to the discovery service. This is likely the IP address of your house, or your office network, but is likely to be a NATed IP address, and a randomly-allocated high-port provided by the NAT device closest to the discovery service.
Any connections across the internet will move directly between the public addresses of the two peers that wish to communicate. Our tunnel establishment will traverse the NAT devices between the two peers, as described above.
We prefer to move traffic via UDP (because there are downsides to tunneling ethernet frames over TCP), but will try both to allow for NAT devices that restrict UDP.
Local IP addresses¶
It would be pretty inefficient if every connection between peers had to go out to the internet, even when users or servers were in the same building. So, when the set of connection candidates is reported to the discovery service, the local agent includes the list of available "local addresses", which are usually the local LAN address of the system, for example 192.168.1.10, or something in the 192.168.1.0/24 subnet or other RFC1918 range.
That way, if there are local routes available to connect the two peers directly, Enclave can use that pathway. The local addresses are the highest priority candidate, so if we can bring up a local connection, we will prefer it over the public address.
Existing private connectivity
Enclave is designed to function alongside existing private connectivity you have, to make it easier to gradually deploy Enclave, rather than having to rip out your existing solution just to try Enclave on a small number of systems.
Enclave will consider any local adapter other than it's own as a valid possible candidate for traffic, so Enclave traffic can move over an existing site-to-site or point-to-site VPN without difficulty.
Traffic relays¶
In some circumstances, a NAT device between two peers can fully block our standard hole-punching attempts; this is generally fairly rare, but can happen. In this scenario, we have a "connectivity of last resort", which is our relay servers.
When we have to use a relay server for a connection, we first select the "best" relay. This is the relay determined to be geographically closest to both peers involved in a tunnel. That is, the relay that results in the shortest total path.
Once a relay is selected, both peers will connect to the relay server's public TCP endpoint. A 128-bit randomly-generated authorisation code is provided to the relay by the discovery service and then by each peer, which sets up bi-directional transparent forwarding of encrypted packets between the two peers. A new authorisation code is generated for each introduction, and can only be used once.
The normal cryptographic handshake we perform ensures that each peer is actually talking to the other, regardless of the network hops in-between.
The handshake and therefore the per-session end-to-end encryption is still established directly between the two peers, without the relay server in the middle having any mechanism by which it can decrypt the data; it's just a simple packet router.
Enclave Discovery Service¶
We've talked about the Discovery Service a bit already, but I'll cover it in more detail here. The Discovery Service fulfills two main roles:
- Enabling introductions
- Enforcing policy
The first point we've already covered a fair bit; the Discovery Service has a connection to both peers, and an understanding of their public addresses. When both peers are ready to communicate, and are allowed to communicate, the Discovery Service facilitates the introduction.
Once the introduction has happened, the Discovery Service is no longer required for exchange, only to build new connectivity, so temporary outages of our platform will not effect existing data pathways.
That allowed to communicate piece brings us to the second part of the Discovery Service's role. When you manipulate policies, tags, enrol, revoke or otherwise manipulate your virtual network configuration in our portal (or via our APIs), the Discovery Service updates the resultant set of policy for your network.
The resultant set of policy is the outcome of all your configuration, and describes the intended virtual network you wish to establish, including policy options, trust requirements, and any other settings.
When the resultant set of policy changes, the discovery service issues policy updates to any affected peers instructing them to bring up, tear down or amend the ACLs on a connection to another peer.
The Discovery Service also continously re-evaluates policies applied to systems, to check whether the trust requirements of a policy are still met. If a trust requirement for a policy is no longer met for a peer, the Discovery Service issues the appropriate disconnect instructions if needed, and prevents further introductions until the trust requirement is met.
We aim to mutate policy and the resultant connectivity pathways in less than 1 second after making a change in the portal. No need to wait 20 minutes for routing tables to refresh, or caches to expire.